

本記事は、生成AIの重要技術であるLLM(大規模言語モデル)の材料開発への応用事例を解説する全2部構成のPart 2です。Part 1では、LLMの化学タスクへの性能や物性予測、実験計画の立案について解説しました。本Part 2では、LLMを利用した自動実験や情報抽出の具体例に焦点を当てます。
LLMを利用した自動実験
LLMの材料開発における活用方法の一つとして、実験ロボットのインターフェースとして用いるというものがあります。従来、実験の自動化には詳細なプログラミングや複雑な指示の統合が必要でしたが、LLMを介することで、これらのプロセスが大幅に簡略化されています。ORGANAはこのような試みの一つです。この研究ではLLMを用いて、人間の化学者からの指示を元に実験計画とロボットアクションの設計を行い、実験結果のレポートの作成までを行うことに成功しています。
ORGANAの仕組み
ORGANAは、LLMを用いて実験計画からロボットの動作設計、さらには結果のレポート作成までを自動化するシステムです。以下のような流れで動きます。
- 指示の受け取り
ORGANAは、化学者からのテキストまたは音声による実験指示を受け取ります。この指示は多くの場合、ラフで抽象的な形式ですが、LLMを用いることで自然言語のまま解釈可能です。 - 実験計画の作成
受け取った指示を基に、LLMが詳細な実験計画を作成します。この段階では、計画内容について化学者とやり取りを行い、計画をブラッシュアップするプロセスも含まれます。たとえば、「化合物AとBを反応させる」という曖昧な指示が、「AとBを特定の温度と濃度で反応させ、生成物Cの収率を確認する」という具体的な計画に変換されます。 - ロボットアクションへの変換
作成された実験計画を基に、LLMがロボットが実行可能なアクションへと変換します。ORGANAでは、CLAIRifyと呼ばれるLLMが使用されており、自然言語で記述された指示を構造化言語に変換する役割を果たします。1-3のプロセスを経て化学者のラフな実験の指示を解釈して具体的なロボットの動作(例: 特定のピペット操作や温度制御)に落とし込むことができます。 - 実験結果の統計処理とレポート作成
実験終了後、ORGANAは得られたデータを統計的に処理し、結果を要約したレポートを生成します。このレポートは、化学者が次の実験計画を立てる際の参考資料としても活用できます。論文では溶解度評価、pH 測定、再結晶化、電気化学実験などを正常に実施できたと報告されています。
このようにLLMは、ロボットと自然言語でやりとりできるインターフェースとしても機能します。これにより従来であれば化学者が詳細に設定を行い注意深くモニタリングする必要があったロボットによる実験の自動化に伴う煩雑な作業を、大幅に軽減する可能性を秘めています。
論文からの情報抽出と要約
材料開発におけるLLMの重要な活用法の一つに、論文からの情報抽出と要約があります。材料科学の研究者は日々大量の論文を参照し、必要なデータを見つけ出すために膨大な時間を費やしています。LLMを活用することで、このプロセスを自動化し、効率的に必要な情報を抽出・整理できます。さらに、抽出した情報をLLMに参考データとして与えることで、より精度の高い回答を得ることが期待されます。
MOF合成における情報抽出の成功例
「ChatGPT Chemistry Assistant for Text Mining and Prediction of MOF Synthesis」では、下記のプロセスにより、MOF合成に関係する論文からMOFの合成条件を抽出して表にまとめています。
- 論文のパート分割
論文の文章をいくつかのパートに機械的に分割します。例えば、1ページを4分割するといった方法である程度の長さの文章の塊に分けていきます。。 - 数値ベクトルへの変換
各パートを数値ベクトルに変換することで、文章同士の「距離」を測定可能にします。この距離情報を基に、実験条件が記述されている可能性が高いパートを特定します。 - LLMによる内容判定
特定されたパートが実際に実験条件に関連しているかを、LLMで判定します。これにより、ノイズとなる無関係な情報を除外します。 - 表形式での情報整理
最終的に、LLMを用いて抽出した条件(例:化合物名、反応温度、触媒など)を表にまとめます。
228本の論文から化合物名や反応温度など11種類の実験条件を抽出するタスクで、95%以上の高精度を達成しました。この手法は、LLMの処理効率を向上させるだけでなく、無関係なノイズとなる情報による精度低下を防ぐという点でも意義があります。
ChatExtractによる高度な情報抽出
「Extracting Accurate Materials Data from Research Papers with Conversational Language Models and Prompt Engineering」では、ChatExtractという手法を提案しています。下記のようなステップにより、論文から主要な情報を抽出します。
- パート分割とデータ有無の判定
論文をパートごとに分け、それぞれのパートに数値データが含まれているかをLLMで判別します。 - データ量の判定
各パートに含まれる数値データが「1つのみ」なのか、「複数」なのかを判定します。 - データの詳細抽出
数値が単一の場合は、物質名、数値、単位に分解して抽出します。複数の場合は、それらを表形式に整理します。単一値は抽出精度が高いため直接処理されますが、複数値の文は誤りが発生しやすいため、追加の検証が行われます(ステップ4)。 - 抽出データの検証
数値が複数の場合は、抽出されたデータと元の文章を照らし合わせ、結果が正しいかを確認します。
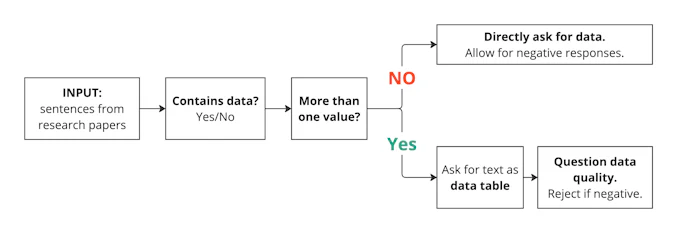
図1. ChatExtractにおける対話型LLMを用いた構造化データの抽出(Credit: Polak, M.P., Morgan, D., Nature Communications, 15, 1569 (2024). https://doi.org/10.1038/s41467-024-45914-8.(CC BY 4.0)を元に、MI-6が図を再構成)
金属ガラスの臨界冷却速度や体積弾性率といった数値を、90%以上の精度で抽出できています。また、数値データだけでなく、化学反応やプロセス条件に関する情報も整理できるという特徴もあります。
以上のように、論文から情報抽出を行う際には単に論文全てをLLMに処理させるのではなく段階的に情報抽出を行うことでより高い精度で知りたい情報を手に入れることができます。
まとめ
本記事では、LLMを材料研究に活用するための技術と具体的な事例について解説しました。LLM単体では対応しきれない専門性の高い課題においては、RAG(検索拡張生成)や化学ツールとの連携が不可欠であることを示しました。これらの技術を適切に活用することで、LLMはその知識のギャップを補い、人間では処理しきれない膨大なデータや文献の要約、そしてそれに基づく推論を行う強力な道具として機能します。
また、ORGANAのような自動実験システムやChemCrowによる化学ツール連携の事例から、LLMを単なる「辞書」として用いるのではなく、「言語処理エンジン」として活用できることがポイントと言えるでしょう。
参考文献
- https://www.tandfonline.com/doi/pdf/10.1080/27660400.2023.2260300?needAccess=true
- https://arxiv.org/abs/2306.11296
- https://doi.org/10.48550/arXiv.2402.11323
- https://pubs.acs.org/doi/pdf/10.1021/acsengineeringau.3c00058
- https://arxiv.org/pdf/2304.05376
- https://arxiv.org/pdf/2401.06949
- https://arxiv.org/pdf/2404.01475
- https://arxiv.org/pdf/2303.05352
























