

LLM(大規模言語モデル)は、生成AIの一種であり、自然言語を効率的に処理し、さまざまなタスクを自動化する強力な技術として注目されています。特に材料科学分野では、化学タスクの推論、物性予測、実験計画の立案、情報抽出や要約の自動化、自動実験といった分野での応用が進んでいます。
miLab記事「LLMの基礎」では、LLMの仕組みやその構成要素であるTransformer、GPT、そして補完技術としてのRAGについて解説しました。本記事では、この基礎知識を踏まえ、LLMが材料開発の分野でどのように応用されているかを具体例を交えて紹介します。
本記事は、2部構成をとります。本Part 1では、LLMの化学タスクへの性能や物性予測、実験計画に焦点を当てます。Part 2では、LLMを利用した自動実験や情報抽出の具体例を紹介します。
この基礎知識を踏まえ、LLMが材料開発の分野でどのように応用されているかを具体例を交えて紹介します。
本記事は、2部構成をとります。本Part 1では、LLMの化学タスクへの性能や物性予測、実験計画に焦点を当てます。Part 2では、LLMを利用した自動実験や情報抽出の具体例を紹介します。
LLMの化学タスクに対する性能と限界
LLMを化学タスクに使用した際の性能については複数の研究があります。例えば「Are large language models superhuman chemists?」では化学タスクに特化したベンチマークであるChemBenchを各種LLMと人間の化学者(※)に解かせて得点を比較しています。結果としてはGPT-4o、LLaMa3.1-405B, cluade3.5(Sonnet)などのハイパフォーマンスなLLMだけでなく、LLaMa3.1-8Bなどの性能があまり高くないモデルでも人間の化学者の平均を上回る結果を残しています。
一方で「Prompt engineering of GPT-4 for chemical research: what can/cannot be done?」では、GPT-4に化合物の性質や物理化学の理論について質問したところ、教科書や専門書レベルの質問には正しく答えられる一方で、学術論文レベルの質問に対しては誤答が多いことが報告されています。
総じて、現状のLLMは化学の基本的な知識は有している一方で学術論文レベルのハイレベルな知識はないため、RAGなどを用いて補う必要があると言えるでしょう。
※ポスドク2名、修士号取得者13名、学士号取得者1名の計16名。大学レベルの化学のコース終了後化学の経験が2年以上あることを条件に選ばれている。
LLMを用いた物性予測と実験計画
LLMのユースケースの一つとして、その推論能力を活用して化学タスクに取り組むことが挙げられます。物性の予測や実験計画の立案について、上述の「Prompt engineering of GPT-4 for chemical research」では、GPT-4の推論能力がさまざまなタスクにおいて検証されています。
物性予測における能力と限界
- 化合物構造の予測 GPT-4が化合物名から構造(SMILES表記)を予測できるかを調べた結果、トルエンのような単純な分子については正確に構造を予測できました。しかし、p-クロロスチレンなどの複雑な分子になると、正確な予測が困難であることが報告されています。これは、LLMが学習したデータ範囲や化学構造の具体的な表現への知識不足によるものと考えられます。
- 物性の推論 TEMPO、4-oxo TEMPO、1-Hydroxy-2,2,5,5-tetramethyl-2,5-dihydro-1 H-pyrrole-3-carboxylic acidの電位がこの順序で増加する理由を説明するタスクでは、GPT-4はTEMPOと4-oxo TEMPOの電位差については正しく推論しました。一方、1-Hydroxy-2,2,5,5-tetramethyl-2,5-dihydro-1 H-pyrrole-3-carboxylic acidの電位が他の2つより高い理由は説明できませんでした。この失敗の原因として、GPT-4がこの化合物の構造を正確に推論できなかった点が挙げられています。
- 前例を基にした新規物性予測 LLMが少数の前例を活用して新たな物性を予測できるかについても検証が行われました。GPT-4は4-cyano TEMPOの電位に関する知識を持たないものの、TEMPOの電位に関する情報を与えることで、正確に推論することに成功しました。しかし、フェロセン誘導体の酸化還元電位の推論には失敗しており、これはフェロセンの特性を理解するための化学知識が不足していることが原因とされています。
実験計画の立案における能力と限界
- ベイズ最適化との比較 実験計画のタスクでは、仮想化合物AとBが反応して目的化合物Cを生成するとともに、Cが連鎖反応を引き起こして副産物Dが生成される状況が設定されました。この条件のもとでCの収率を最大化するAとBの濃度および反応時間を最適化するタスクにおいて、GPT-4は初期条件を適切に設定し、ベイズ最適化よりも少ない試行回数で条件を最適化することに成功しました。
- ブラックボックス最適化の課題 一方で、ブラックボックス最適化問題では、GPT-4が最初に設定した誤った仮定を修正できず、問題解決に失敗する場合がありました。たとえば、5変数の2次関数の最大値を求めるタスクにおいて、この関数を1次関数と仮定した場合に、その仮定に反する結果が得られても仮定を修正できませんでした。この結果は、LLMが未知の問題に取り組む際に自己修正能力が不足していることを示しています。初期仮定を誤った場合でも柔軟に修正できるモデルの自己修復能力の向上が必要とされています。
上記の結果から、LLMは物性予測や実験計画において、事前知識の範囲内では優れた推論能力を発揮する一方で、未知の領域や複雑な課題においては限界が顕著でした。ここからも、適切なデータベースを活用したRAGの重要性がわかります。
化学ツールを利用したLLMの拡張
これまで紹介した研究例からも明らかなように、GPT-4などの高性能なLLMであっても、化学タスクに対する能力は依然として限られています。特に、複雑な化学反応予測や高度な実験計画を行う際には、専門的な知識や計算能力が不足しています。そこで、化学ツールと連携させることでLLMを拡張しようというアイディアがあります。
ChemCrowは、このアイディアに基づいて開発された化学専門のLLMツールです。ユーザから与えられたタスクをLLMが単独で解決するのではなく、複数の化学ツールを適切に選択・統合し、それらを用いてタスクを遂行します。
ChemCrowの動作手順
- ツールのカタログ化
ChemCrowには、あらかじめ複数の化学ツールの機能、典型的な入力と出力形式がリスト化されています。このリストにより、LLMは各ツールの用途を理解し、タスクに応じた最適なツールを選択できます。 - タスクの分析
ユーザーから与えられたタスク(例: 化学反応の予測や反応メカニズムの考察)をLLMが解析し、どのツールを使用すべきかを判断します。この際、タスクの複雑さや必要な計算資源を考慮に入れます。 - ツールの実行と結果の収集
ChemCrowは選択したツールに対して入力データを提供し、生成された出力を受け取ります。結果に応じてLLMは別のツールを追加で使用するか、結果をまとめて出力するかなどを判断します。この手順は最終的な結果が得られるまで繰り返されます(→ステップ4)。 - タスクの再評価とツールの再選択
必要に応じて、LLMは追加のツールを利用したり、再度ツールを実行したりすることで、タスクを完成に近づけます。 - 最終結果の出力
すべてのプロセスが終了した後、LLMは結果を整理し、ユーザーに回答します。
ChemCrowの性能
ChemCrowをGPT-4を基盤として構築した場合、GPT-4単体と比較して、複雑な化学タスクでのパフォーマンスが大幅に向上することが報告されています。たとえば、EthylidenecyclohexaneとHBrを混合した場合の生成化合物、およびさらにmethyl peroxideを追加した場合の反応メカニズムを考察するタスクでは、化学の専門家による評価がGPT-4では7.1/10だったのに対し、ChemCrowでは9.8/10という高いスコアが得られました。化学ツール連携によってLLMの欠点を補うことで、より正確かつ信頼性の高い反応メカニズムの考察が得られることを示しています。
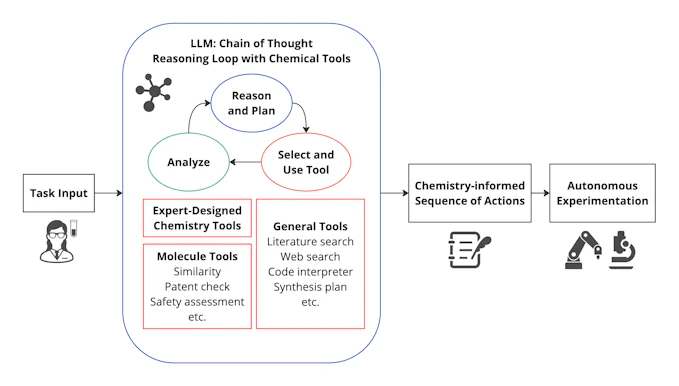
図1. 化学ツールとの連携によるLLM拡張の概念図 (Credit: M. Bran, A., Cox, S., Schilter, O. et al., https://doi.org/10.1038/s42256-024-00832-8.(CC BY 4.0)を参考に、miLab編集部が作成)
ChemCrowは、このアイディアに基づいて開発された化学専門のLLMツールです。ユーザから与えられたタスクをLLMが単独で解決するのではなく、複数の化学ツールを適切に選択・統合し、それらを用いてタスクを遂行します。
ChemCrowの動作手順
- ツールのカタログ化
ChemCrowには、あらかじめ複数の化学ツールの機能、典型的な入力と出力形式がリスト化されています。このリストにより、LLMは各ツールの用途を理解し、タスクに応じた最適なツールを選択できます。 - タスクの分析
ユーザーから与えられたタスク(例: 化学反応の予測や反応メカニズムの考察)をLLMが解析し、どのツールを使用すべきかを判断します。この際、タスクの複雑さや必要な計算資源を考慮に入れます。 - ツールの実行と結果の収集
ChemCrowは選択したツールに対して入力データを提供し、生成された出力を受け取ります。結果に応じてLLMは別のツールを追加で使用するか、結果をまとめて出力するかなどを判断します。この手順は最終的な結果が得られるまで繰り返されます(→ステップ4)。 - タスクの再評価とツールの再選択
必要に応じて、LLMは追加のツールを利用したり、再度ツールを実行したりすることで、タスクを完成に近づけます。 - 最終結果の出力
すべてのプロセスが終了した後、LLMは結果を整理し、ユーザーに回答します。
ChemCrowの性能
ChemCrowをGPT-4を基盤として構築した場合、GPT-4単体と比較して、複雑な化学タスクでのパフォーマンスが大幅に向上することが報告されています。たとえば、EthylidenecyclohexaneとHBrを混合した場合の生成化合物、およびさらにmethyl peroxideを追加した場合の反応メカニズムを考察するタスクでは、化学の専門家による評価がGPT-4では7.1/10だったのに対し、ChemCrowでは9.8/10という高いスコアが得られました。化学ツール連携によってLLMの欠点を補うことで、より正確かつ信頼性の高い反応メカニズムの考察が得られることを示しています。
Part2へ
ここまでで、LLM(大規模言語モデル)の化学タスクにおける性能や物性予測・実験計画の立案能力について解説しました。この続きはPart 2でお届けします。Part 2では、LLMを利用した自動実験や情報抽出の実践事例についてご紹介します。
参考文献
- https://www.tandfonline.com/doi/pdf/10.1080/27660400.2023.2260300?needAccess=true
- https://arxiv.org/abs/2306.11296
- https://doi.org/10.48550/arXiv.2402.11323
- https://pubs.acs.org/doi/pdf/10.1021/acsengineeringau.3c00058
- https://arxiv.org/pdf/2304.05376
- https://arxiv.org/pdf/2401.06949
- https://arxiv.org/pdf/2404.01475
- https://arxiv.org/pdf/2303.05352
























